Favaの仕訳帳ページの読み込みを高速化する
Favaは、Beancountの台帳の中身を見るための強力なウェブUIです。しかし、仕訳の数が多い場合に仕訳帳ページの読み込みに時間がかかるという長年の問題がありました。私はBeancountを5年以上使っており、台帳には15k件以上の仕訳があります。仕訳帳ページが表示されるまでに数秒かかります。
どうやらこの問題の影響を受けているのは私だけではないようです。私よりもはるかに大きな台帳を持っている人もいます。過去に2種類の提案を見た記憶があります。
- 期間を指定して仕訳帳を開く。
- 台帳を年ごとに分割し、Favaでは一度に1年分だけ開くようにする。
私はそのような提案に従うのは難しいと感じ、むしろ仕訳帳ページを全く開かないようにしていました。しかし、意図的であろうとなかろうと、時々開くことがあり、そのたびにイライラさせられました。そこで、この問題を調査し、何か改善できないか見てみることにしました。
最初の試み
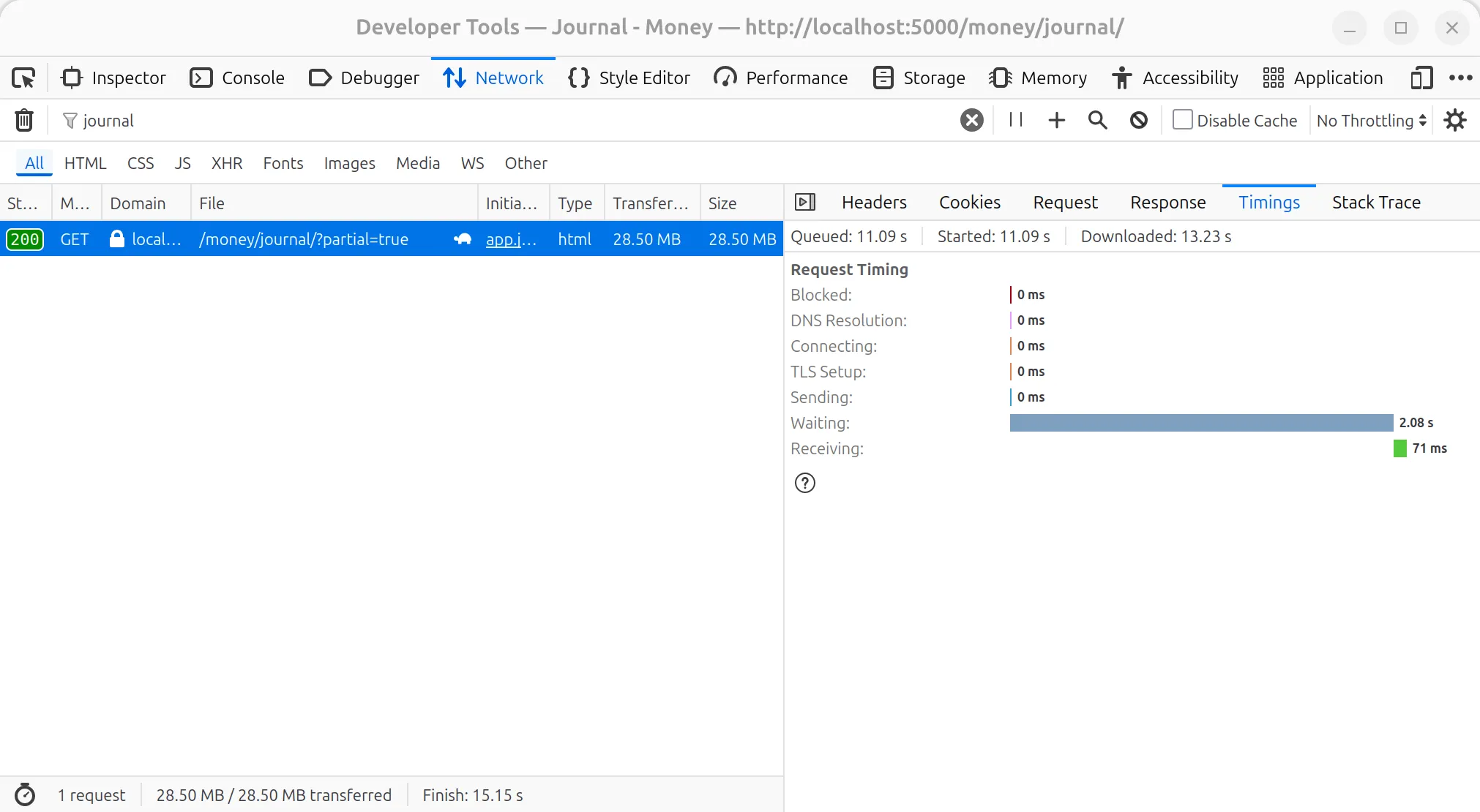
最初に行ったのは、何が原因で遅くなっているのかを調べることでした。最初の調査はかなり前に行ったもので、2022年頃に調べ始めたのですが、その頃は台帳の仕訳が4k件ほどしかありませんでした。記憶しているのは、まず仕訳帳ページのリクエストのネットワークタイミングを見たことです。「Waiting」のフェーズに長い時間がかかり、ページサイズもかなり大きいのです。そして、FavaのPythonコードをプロファイリングしたところ、大半の時間はテンプレートエンジンであるJinjaが仕訳帳テーブルのテンプレートをレンダリングするのに費やされていました。
テンプレートエンジンには、手軽に改善できるような明らかな点はありませんでした。そのため、おそらく単に生成されるコンテンツが多すぎるのだろうと考え、最初に試したのは生成されるコンテンツの量を減らすことでした。
priceエントリ(価格情報)が仕訳帳に表示されないことに気づきました。仕訳帳のすべての仕訳は、デフォルトで次のCSSルールによって非表示になっています。
.journal > li {
display: none;
}そして、各種類の仕訳は、対応するトグルがオンになっている場合にのみ表示されます。priceエントリにはトグルがありませんが、それにもかかわらず生成されるコンテンツには含まれています。その観察に基づき、私が行った最初の変更は、テンプレートでpriceエントリのレンダリングを単にスキップするというものでした。
これがどれだけ役立つかは、priceエントリの数によります。私の場合、毎月約20のコモディティの価格を自動で取得しており、年間で約250件が蓄積されます。これは私の全仕訳の約7%に相当します。大きな量ではありませんが、1行の簡単な変更で済むことを考えると、改善する価値はあります。
同じ考え方で、記帳を最初のレンダリングに含めるのではなく、オンデマンドで読み込むことはできないかという質問を提起しました。私には、記帳は取引のインジケーターをクリックしたときにしか表示されないように見えますが、それらがテンプレートからレンダリングされるコンテンツのかなりの部分(私の場合60%以上)を占めています。めったに必要としないもののレンダリングに60%もの時間を費やすのは、非常に無駄に感じます。しかし、これにはいくらか反発がありました。というのも、トグルを有効にして記帳を常に表示したいユーザーもいるからでしょう。
ページネーション
台帳の仕訳数が増えるにつれて、この問題は徐々に私を悩ませるようになりました。エージェント型AI開発ツール1の存在に勇気づけられ、より将来を見据えたアプローチで再度この問題に取り組んでみることにしました。
以前からあったアイデアの一つに、仕訳帳をページネーション化して、一度にすべてをレンダリングする必要がないようにするというものがありました。最初に表示される部分を先にレンダリングし、残りは後から処理するのです。そして、これが私が実装した内容です。
Favaはjournal.htmlテンプレートから仕訳帳ページをレンダリングします。このテンプレートは_layout.htmlの骨格と、_journal_table.htmlの主要な仕訳帳テーブルを含んでいます。ベーステンプレートである_layout.htmlは、リクエストに?partial=trueが指定されていない場合に、すべてのFavaページの骨格を表示します。他のページから仕訳帳ページに切り替える際、ブラウザは実際には/journal/?partial=trueをリクエストして、テーブル部分だけを取得します。
仕訳帳テーブルは次のような構造になっています。
<fava-journal>
<ol class="flex-table journal">
<li class="head">
<!-- テーブルヘッダー -->
</li>
{% for entry in entries %}
<li><!-- 仕訳レンダリング --></li>
{% endfor %}
</ol>
</fava-journal><fava-journal>は、フロントエンドのFavaJournalクラスによって処理されるカスタム要素です。
この構造を踏まえて、私の計画は次の通りでした。
journal.htmlテンプレートでページネーションを行う。仕訳数がページごとの上限を超えた場合、仕訳をスライスし、最初のスライスを返すと同時に、<fava-journal>カスタム要素の属性を介して総ページ数を渡す。- 次に
FavaJournalクラスで、その属性が存在する場合、残りのすべてのページを並行して取得し、リストに順次追加していく。
この計画はうまくいきました。これにより、最初のページレンダリングが大幅に短縮され、仕訳帳ページをより早く見ることができるようになりました。しかし、一つ問題がありました。それは順序です。
ほとんどの人は、仕訳帳ページには最新の仕訳が最初に表示されることを予想すると思います。少なくとも、私はそう予想していますし、Favaのデフォルトの動作もそうなっています。しかし、テンプレートへの入力は仕訳を時系列順、つまり最も古い仕訳が先頭に来るようにリストアップします。しかし、仕訳帳ページのソート機能の実装方法により、ページ付けの順序を変更することは、入力データを逆にするほど簡単ではありません。
上記のテンプレートに戻ると、テーブルヘッダー部分には次のような要素があります。
<span class="datecell" data-sort="num" data-sort-name="date">日付</span>
<span class="flag" data-sort="string" data-sort-name="flag">F</span>そして、各項目には次のようなものがあります。
<span class="datecell" data-sort-value="{{ loop.index }}">{{ entry.date }}</span>
<span class="flag">{{ entry.flag }}</span>ソートのコードが行うのは、ヘッダーのdata-sortとdata-sort-nameを解析し、リスト内の項目を対応する要素のdata-sort-valueの値、またはそれが利用できない場合はテキストコンテンツに基づいてソートすることです。これまでFavaは、日付でソートした際にBeancountの内部の仕訳順序に従うように、日付フィールドのソート値としてループのインデックスを使用してきました。しかし今では、ソート値はページネーションと逆順の両方を考慮に入れる必要があります。
最初は、負のソート値を使うなど、小賢しい方法を実装しました。Favaのメンテナーと相談した結果、各項目にインデックスを生成し、それを使ってこのソート値を埋めることで順序の正しさを保証するという方法に落ち着きました。2
Flexbox
私が行ったもう一つの小さな最適化は、仕訳帳テーブルでdisplay: flexを使うようにしたことです。これは、ソートのコードをプロファイリングしているときに見つけたものです。デフォルトのdisplay: blockでは、すべての子要素が単なるブロックであることを意図しているにもかかわらず、Firefoxは(テキストの)行の解決にかなりの時間を費やしているようでした。この場合にdisplay: flexに切り替えると、Flexboxは行を扱わないため、DOMの更新に費やされる時間が大幅に削減されます。
しかし、この最適化はChromeには影響しないようです。Firefoxのブロックレイアウトアルゴリズムには、何らかの最適化の機会があるのかもしれません。
まとめ
これで、仕訳帳ページの読み込みがずっと速くなりました。台帳の仕訳数が多くても、ページはすぐに表示されます。実際には、ページを読み込むのにさらに時間がかかる可能性がありますが、体感パフォーマンスははるかに向上し、より早く操作できるようになります。また、(読み込み完了後には)すべてのコンテンツがページ内に存在する、という特徴も維持されています。そのため、ユーザーがページ内検索を行ったり、特定の位置までスクロールして過去の時点に素早くジャンプしたりしたい場合でも、これまで通り迅速に行うことができます。
長期的には、メンテナーはレンダリングをフロントエンドに移行し、将来的には仮想リストを使用する方向で検討していると述べています。これは合理的なアプローチと思います。少なくとも、バックエンドとブラウザ間で渡されるデータ量を大幅に削減し、ソートのような機能の扱いをより簡単にし、エラーが発生しにくくする可能性があります。また、パフォーマンスも向上する可能性が高いです。その理由は、
- ローカルの設定により適応したレンダリングが可能になること(例:非表示の仕訳をレンダリングしない、デフォルトで記帳をレンダリングしない、直接正しい順序でレンダリングする)、そして
- 一般的に、PythonよりもJavaScriptとそのフレームワークを高速化するためにはるかに多くのリソースが投入されてきたこと、の両方によります。
仕訳帳のレンダリングをクライアントサイドに移行することを検討している、他の人によるドラフトPRがあります。これは大きな変更ですが、大きなメリットももたらしてくれることを期待しています。仕訳帳ページは、まだサーバーサイドでレンダリングされている唯一の主要なページのようです。
しかし、今のところは、ページネーションが最小限の変更でページを高速化する、まあまあの落とし所でしょう。